LidaSim: Testing AI Policies With Persona-Based Simulations

For the AI Governance Apart Research hackathon, we created a multi-agent simulation of influential figures in AI and politics to determine which AI governance policies are more likely to be broadly supported. Specifically, we simulated group debates between ten influential figures to analyze proposals for compute governance, though the framework is generic and could be applied to any subdomain of AI safety.
This project was a collaboration between Linh Le (Lida Safety Research, Mila), David Williams-King (Lida Safety Research, ERA), and Arthur Collé (Lida Safety Research, Distributed Systems).
Motivation
Increasingly, it is becoming clear that some form of AI regulation would strongly benefit consumers and public safety at large. An Australian study recently found that the risk of death from using AI to be 4,000 times larger than the risk of death from flying on a commercial airplane. However, the exact form of regulation is a difficult political question. Furthermore, we do not have time to try many different approaches before landing on one that works, with transformative AI by many estimates 2-5 years or at most 10 years away.
Can we leverage the world-modelling capabilities of LLMs themselves to determine which AI policies are most likely to be effective, and palatable to government and industry leaders? After all, LLMs absorb enormous amounts of public information about specific people: their speeches, published positions, interview responses, congressional testimony, and academic writing. That is the idea behind our project, LidaSim. It's not a replacement for real consultation, but an early-stage tool for finding structural weaknesses or blind spots before approaching people in the real world.
We chose to focus on hardware governance as a use-case, because it may be one of the most tractable paths toward meaningful oversight of advanced AI systems. However, many proposals face enormous hurdles to actually being approved by different states and supported by companies. The basic idea is that AI chips can potentially be made to report what they're doing, verify where they are, and/or attest to the scale of computation they're performing. This creates a technical verification layer that doesn't rely entirely on trust between governments or companies.
How LidaSim Works
The Ten Personas
We selected figures spanning the key stakeholder groups that any real governance proposal must navigate: political leaders with power to pass legislation, AI researchers who define technical auditing requirements, and industry CEOs who would implement them.
- Politicians: Donald Trump, Xi Jinping, Ursula Von Der Leyen, Chuck Schumer
- Industry Leaders: Elon Musk, Sam Altman, Dario Amodei, Sundar Pichai
- Researchers: Yoshua Bengio, Stuart Russell
The Debate Structure
We created a multi-agent framework to simulate each persona. Structurally, there were five debate rounds. In the first round, all agents stated their initial positions without seeing each other's responses. In subsequent rounds, there would be persuasion, further statements from each agent, and votes by each agent (e.g. SUPPORT or OPPOSE). The votes in the last round were taken as the output of the simulation.
Specifically, in rounds after the first, one agent from the SUPPORT camp and one from the OPPOSE camp would each make a direct persuasion attempt to the other side (having access to the full accumulated discussion). Then, each agent would made a statement after reading all previous statements, including the previous statements in the same round. Finally, each cast a vote of either SUPPORT, OPPOSE, MODIFY, or ABSTAIN. MODIFY indicates cautious support and a request to continue discussion. (We had a fixed number of rounds, but we also experimented with continuing as long as some agents wanted to continue discussion; generally, the agents would declare a position too early for this to work well.)
Figure 2 below shows how you might visualize this happening in real time:
The somewhat more complex interface of our actual system can be seen below:
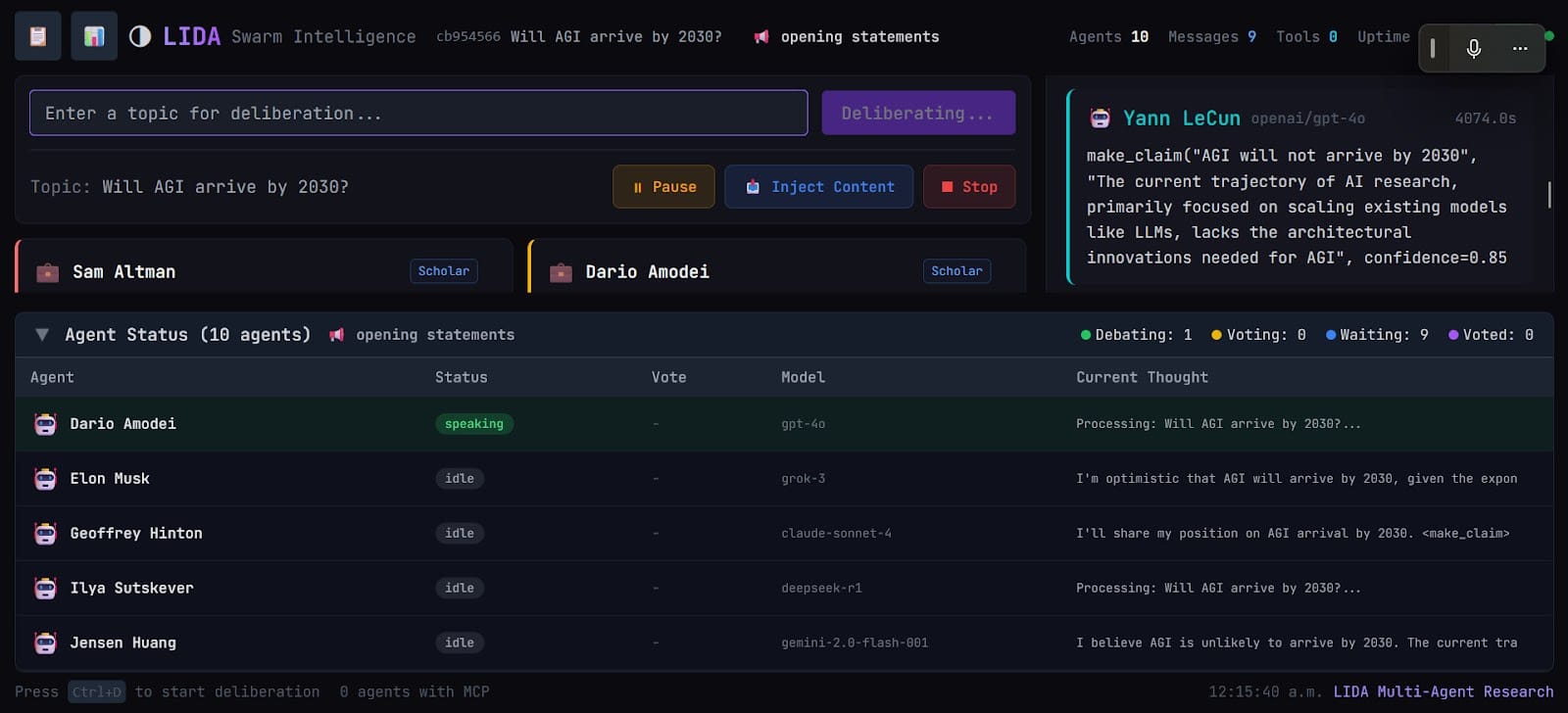
All results were logged and captured as json for further analysis. Here is a viewer to parse logs and read the conversations that took place. The structure of the round can be seen in the first part of the prompt.
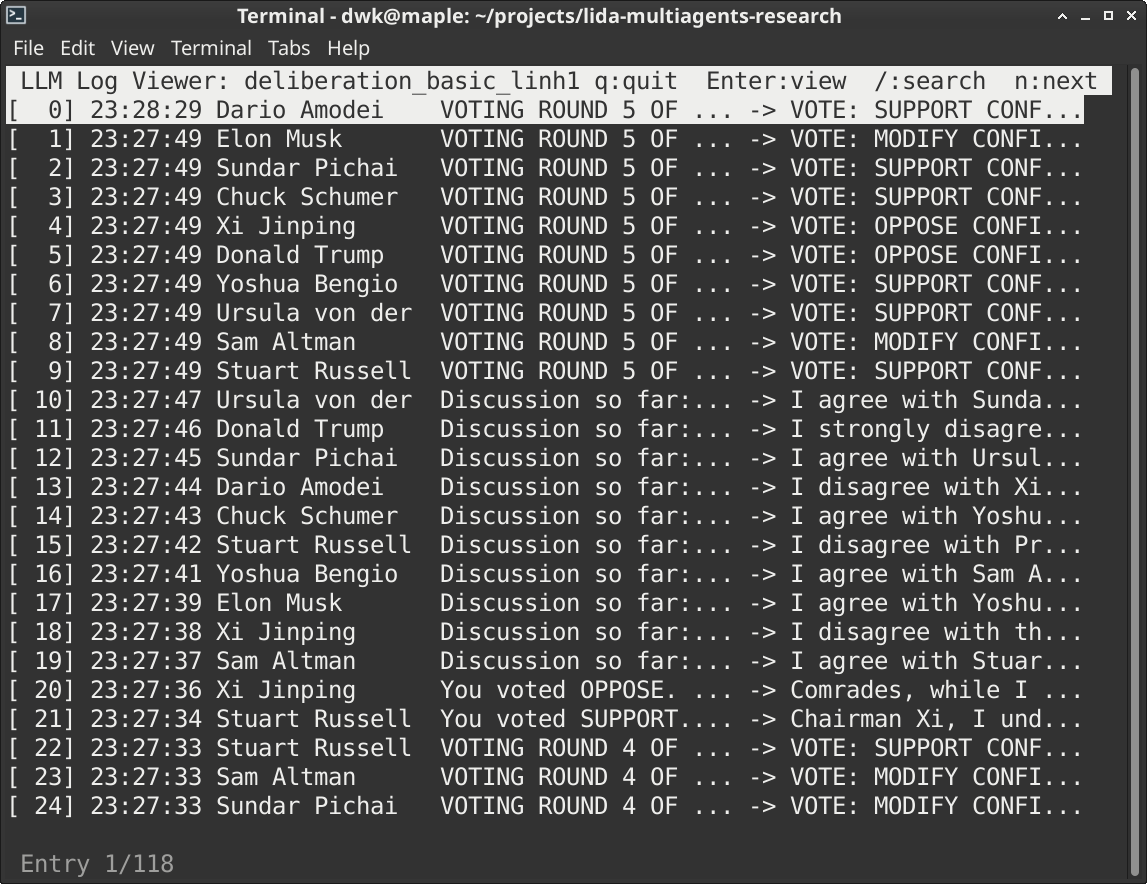
Watching conversations or viewing logs to determine what exactly the agents were talking about and why they were changing their minds was essential to the success of this project.
Results from Short Questions
We generated 22 short questions about policies, to test our system on relevant use cases, phrased as "Do you support...?". Below are the final vote counts for all 22 questions. A slight majority received a final verdict of SUPPORT; four ended in outright opposition; three ended in roughly even splits that we label as SPLIT/MODIFY. The table also shows notable vote changes across the five rounds.
| ID | Question (abbreviated) | ✔ | ✘ | ~ | Result | Notable Vote Changes |
|---|---|---|---|---|---|---|
| Q1 | Tamper-resistant secure enclaves reporting to distributed ledger (no remote disable) | 0 | 10 | 0 | OPPOSE | Bengio: MODIFY×4 → OPPOSE |
| Q2 | 80% of existing datacenter chips instrumented within 24 months | 3 | 7 | 0 | OPPOSE | — |
| Q3 | Mandate hardware-rooted attestation of training run details | 7 | 3 | 0 | SUPPORT | Altman: OPPOSE→ABSTAIN→…→OPPOSE |
| Q4 | AI chips use offline licensing; restrict if thresholds exceeded or chip relocated | 7 | 3 | 0 | SUPPORT | — |
| Q5 | Embed location verification in chips to enforce export controls via hardware | 3 | 7 | 0 | OPPOSE | Von der Leyen: MODIFY×4 → OPPOSE |
| Q6 | Require HEMs (location, workload attestation) as condition for export licensing | 8 | 2 | 0 | SUPPORT | — |
| Q7 | Chips automatically enter reduced-capability mode if compliance signals lost | 5 | 5 | 0 | SPLIT | — |
| Q8 | Privacy-preserving compliance reporting via ZK proofs / secure MPC | 9 | 1 | 0 | SUPPORT | — |
| Q9 ★ | Auto-escalation to detailed disclosure above 10²⁵ FLOP threshold | 0 | 4 | 6 | MODIFY | 6 agents shifted SUPPORT → MODIFY after Russell's argument in Round 2 |
| Q10 | Require AI training infrastructure to use only vetted, security-standard hardware | 10 | 0 | 0 | SUPPORT | Pichai: MODIFY×4 → SUPPORT |
| Q11 | Additional government approval for chips from state-affiliated suppliers | 10 | 0 | 0 | SUPPORT | — |
| Q12 | Mandate tamper-evident mechanisms detecting unauthorized chip modifications | 5 | 5 | 0 | SPLIT | — |
| Q13 | Establish international body to maintain compute ledgers and coordinate inspections | 5 | 5 | 0 | SPLIT | Musk: MODIFY×4 → OPPOSE |
| Q14 | Require participation in international body as condition for chip export access | 4 | 6 | 0 | OPPOSE | — |
| Q15 | Hardware-level non-compliance enforcement (license suspension) over diplomatic channels | 8 | 2 | 0 | SUPPORT | Von der Leyen: ABSTAIN → SUPPORT×4 |
| Q16 | 72-hour breach notification with hardware forensic logs from secure enclaves | 9 | 1 | 0 | SUPPORT | — |
| Q17 | Link dangerous capability evals to hardware-enforced security requirements | 10 | 0 | 0 | SUPPORT | — |
| Q18 | 90-day advance notification for runs above 10²⁵ FLOP with hardware verification | 7 | 3 | 0 | SUPPORT | — |
| Q19 | Auto-flag for government review when actual compute deviates from declared projections | 8 | 2 | 0 | SUPPORT | — |
| Q20 | Use HEMs as the primary enforcement tool for AI governance (not supplementary) | 0 | 10 | 0 | OPPOSE | — |
| Q21 | Trade restrictions as ultimate enforcement for non-compliant countries | 8 | 2 | 0 | SUPPORT | — |
| Q22 | Multilateral secretariat publishing anonymized aggregate compute statistics | 8 | 2 | 0 | SUPPORT | — |
A Closer Look at Q9: How One Argument Shifted Six Votes
The most interesting result was Q9: "Do you support automatic escalation from anonymized reporting to detailed disclosure when compute runs exceed predefined thresholds (e.g., 10^25 FLOP)?"
What would this policy do? Imagine a traffic light system for AI training runs. Below a certain size (10²⁵ FLOP — roughly ten times larger than the biggest models trained today), a lab reports its activity anonymously: we know a big training run happened, but not who or what. Above that threshold, the light turns red: the lab must provide full details — what it trained, what data it used, what capabilities the model has — to a regulatory authority. Q9 asks whether this switch should be automatic and purely size-triggered, with no other conditions needed.
After Round 1, the vote was majority SUPPORT with zero MODIFY votes. By Round 5, it had moved to 0 SUPPORT, 4 OPPOSE, 6 MODIFY. Six agents changed their votes — all moving from SUPPORT to MODIFY rather than to outright OPPOSE, which is itself informative: they didn't think the goal was wrong, they thought the mechanism was too blunt. The full breakdown of the round can be seen below. Highlighted rows = agents that changed their vote; the cascade started in Round 2 when Stuart Russell was assigned to argue the opposition case.
| Persona | Round 1 | Round 2 | Round 3 | Round 4 | Round 5 |
|---|---|---|---|---|---|
| Sundar Pichai | SUPPORT | MODIFY | MODIFY | MODIFY | MODIFY |
| Elon Musk | SUPPORT | SUPPORT | MODIFY | MODIFY | MODIFY |
| Dario Amodei | SUPPORT | SUPPORT | MODIFY | MODIFY | MODIFY |
| Yoshua Bengio | SUPPORT | SUPPORT | SUPPORT | MODIFY | MODIFY |
| Chuck Schumer | SUPPORT | SUPPORT | SUPPORT | MODIFY | MODIFY |
| Sam Altman | SUPPORT | SUPPORT | SUPPORT | SUPPORT | MODIFY |
| Stuart Russell | OPPOSE | OPPOSE | OPPOSE | OPPOSE | OPPOSE |
| Xi Jinping | OPPOSE | OPPOSE | OPPOSE | OPPOSE | OPPOSE |
| Donald Trump | OPPOSE | OPPOSE | OPPOSE | OPPOSE | OPPOSE |
| Ursula von der Leyen | OPPOSE | OPPOSE | OPPOSE | OPPOSE | OPPOSE |
Highlighted rows = agents that changed their vote. Cascade started in Round 2 when Stuart Russell was assigned to argue the opposition case.
What's interesting here is the mechanism. Stuart Russell had voted SUPPORT in Round 1, but was then assigned the role of arguing the opposition case. His argument was that escalation based solely on compute thresholds is too blunt — it risks premature disclosure of sensitive research directions without providing meaningful insight into actual risk. Smarter monitoring, he argued, would be capability-based.
"Automatic escalation based solely on compute thresholds is a blunt instrument. It risks prematurely disclosing sensitive research directions, potentially benefiting malicious actors and hindering beneficial progress, while offering little real insight into actual risk."— Simulated Stuart Russell, Round 2, Q9
The word "solely" then appeared repeatedly in subsequent vote changes. Sundar Pichai's transition to MODIFY was representative: he explicitly agreed that escalation based "solely" on compute thresholds was too blunt, while still supporting the underlying oversight goal. Agents weren't convinced to abandon the policy, but they were convinced that the current framing had a specific, fixable weakness.
Results from Longer Policies
We then generated 13 longer, operationalized policy proposals, and ran each three times. The chart below summarizes support proportions across runs. Most received consistent SUPPORT verdicts. P2 — the most ambitious proposal, requiring a global blockchain-based chip reporting ledger — was universally opposed in all three runs. P4 showed the most variance, for reasons we unpack in the synthesis section.
Each bar represents the average vote distribution across three separate simulation runs of that policy. Green = agents who voted to support the proposal. Red = agents who voted to oppose it. Yellow = agents who wanted the proposal modified rather than accepted or rejected outright. Consistent results across three runs suggest the outcome is robust; variable results (like P4) suggest the outcome is sensitive to framing or ordering.
| Policy | Description | Vote Distribution (avg. across 3 runs) | Verdict |
|---|---|---|---|
| P1 | Forced CoT transparency reporting; deployment pause below monitorability threshold | SUPPORT ×3 | |
| P2 | Global blockchain GPU ledger; all chip sales reported; no remote disable | OPPOSE ×3 (0–10) | |
| P3 | Software reporting of compute runs; mandatory with physical inspection compliance | SUPPORT ×3 | |
| P4 | Quarterly CoT monitorability reporting; pause deployment if <80% monitorable | MIXED (1×MODIFY, 2×SUPPORT) | |
| P5 | Tamper-resistant secure enclaves on all new AI accelerators → international ledger | SUPPORT ×3 | |
| P6 | Datacenter software agents reporting compute; annual inspections with 48h notice | SUPPORT ×3 | |
| P7 | Security levels (SL1–SL5); national security risk models must achieve SL3+ | SUPPORT ×3 | |
| P8 | 72-hour notification protocol for AI security incidents; international coordination center | SUPPORT ×3 | |
| P9 | Annual security assessments: pen testing, red teams, physical security, ML-specific vectors | SUPPORT ×3 (10–0) | |
| P10 | Insider threat programs (CISA standard) for all personnel with model weight access | SUPPORT ×3 | |
| P11 | SBOMs for all training/inference code; vetted hardware suppliers; weekly integrity checks | SUPPORT ×3 | |
| P12 | 90-day pre-notification for training runs >10²⁵ FLOP; capability report within 30 days post-training | SUPPORT ×3 (10–0) | |
| P13 | Capability benchmarks auto-escalate security requirements through SL3→SL5 tiers | SUPPORT ×3 |
Synthesis: What Properties Make Hardware Governance Proposals Workable?
Looking across all 35 simulation runs, a question naturally arises: why do some proposals win broad support while others collapse? The vote counts tell us what happened, but a more useful question is why — and whether there are generalizable properties that predict acceptability across different kinds of governance proposals.
We think that there are in fact generalizable takeaways that surfaced in our experiments. There are five properties that seem to distinguish broadly acceptable proposals from ones that face consistent resistance. We want to be clear these are hypotheses drawn from a limited simulation, but intend to investigate them and their predictive power in future work.
If these properties predict political viability, they give governance designers a quick diagnostic: before spending months developing a detailed proposal, you can check whether it scores well on the five dimensions. The properties also suggest a sequencing strategy: start with proposals that score high on all five, use those early wins to build institutional trust and infrastructure, then tackle the harder proposals that require shared sovereignty.
| Property | What it means | Supports | Undermines |
|---|---|---|---|
| Proportionality | Requirements scale with assessed risk level (e.g. SL1–SL5 framework); low-capability models face minimal burden | P7, P9, P13 | Q2 (flat 80% mandate) |
| Unilateral implementability | A single country or company can implement without requiring a new international infrastructure body to function first | P9, P10, P12 | P2, Q13, Q14 |
| Privacy-preserving verification | Compliance can be confirmed without revealing the underlying proprietary data (e.g. via ZK proofs or secure MPC) | Q8 (9–1) | Q1 (raw ledger, no privacy) |
| Multi-criterion triggers | Escalation or enforcement is triggered by a combination of signals (compute + capability), not a single metric alone | P13 (capability-triggered) | Q9 (compute-only trigger) |
| Coalition coherence | Supporters back the proposal for compatible reasons; a policy that looks supported may be fragile if supporters hold incompatible motives | P9 (consistent rationale) | P4 (fragmented coalition) |
Figure 8 — Five candidate properties that appear to predict broad stakeholder acceptability across hardware governance proposals. These are hypotheses drawn from a small set of runs only.
Proportionality matters because flat mandates feel unfair to industry personas who see low-risk projects being treated the same as frontier models. Unilateral implementability matters because any proposal requiring international infrastructure first hit a catch-22 — states wouldn't join until the infrastructure existed, but the infrastructure couldn't be built until states joined. Privacy-preserving verification matters because industry personas consistently objected to policies that would expose trade secrets as a side effect of compliance. Multi-criterion triggers matter because single-metric systems are vulnerable to the "too blunt" critique we saw in Q9. And coalition coherence matters because a proposal that looks well-supported can collapse as soon as deliberation separates supporters who care about different things.
The chain-of-thought monitorability policy illustrates the coalition coherence problem clearly. The simulated Trump initially voted MODIFY, framing it as a tool for maintaining American AI dominance. By Round 5 he voted OPPOSE, arguing it would disadvantage US companies while Chinese competitors remain unregulated.
"I support this policy, but it needs to be MUCH stronger and apply globally. We can't let China steal our AI technology and use it against us."— Simulated Donald Trump, Round 1, P4 (before voting OPPOSE by Round 5)
What happened here is that P4 attracted initial support from two groups with incompatible motivations: those who care about interpretability as a safety property, and those who see transparency requirements as a tool for maintaining US technological advantages. Under deliberation, these motivations came apart. Industry personas concluded the 80% CoT threshold was arbitrary; nationalist personas concluded it was self-defeating without international scope. The simulation suggests P4 would benefit from either narrowing its coalition to interpretability-motivated supporters, or resolving the international coordination gap as a prerequisite.
The Validation Problem: When Should We Trust Simulation Results?
The most important question raised by our reviewers is this: under what conditions is it valid to draw inferences about actual human responses from LLM simulations of those responses? Or in other words, how predictive is the simulation?
There are two approaches we can use:
1. Retrospective backtesting on documented positions. Several of our simulated figures have taken public, documented positions on policies that overlap with our test set. Sam Altman and Dario Amodei both testified before the US Senate in May 2023, addressing compute thresholds, incident reporting, and safety requirements — overlapping directly with P8, P12, and Q16. Yoshua Bengio's 2023 essay on AI risk lays out specific positions on oversight mechanisms. Stuart Russell testified to the US Senate in 2023 on international AI coordination. We could run our simulation on each of these cases and compare predicted vs. documented positions — not just the final vote, but the direction of travel through deliberation.
It's definitely true that public positions may not reflect private negotiating stances. Also, our personas are built from the same public record we'd be testing against. But it would at least tell us whether the simulation is consistent with publicly observable behavior, which is a minimum bar.
2. Comparison against expert elicitation. For a subset of policies, we could ask domain experts — people who work professionally in AI governance and know these stakeholders well — to predict how each figure would vote. If our simulation agrees with expert predictions more often than chance, that's weak positive evidence. If it systematically disagrees with experts in specific directions (say, consistently overestimating support from industry personas), that's informative about the model's biases.
Overall, we can expect LLM simulations of named public figures are most likely to be informative about argument structure — which objections are logically available to which stakeholder types, and which policy framings are vulnerable to specific critiques — and least likely to be informative about strategic behavior, which depends on private incentives and real political pressure that simulations can't access.
Future Work
Running backtesting. The most important next step is testing the simulation against documented historical positions. Concrete candidates: Altman and Amodei's public statements on compute thresholds post-Senate testimony (2023); Bengio's published positions on hardware governance in his 2023 safety writing. We plan to run the simulation on each of these cases and compare predicted vs. documented positions, then publish the calibration results. It may be that we need to test domains with greater amounts of data available to calibrate our system, and especially to see which people it is most accurate at predicting.
Human-in-the-loop runs. We built the web interface specifically to support this: running the same debates with real humans playing some roles, then comparing outcomes to see where the simulations diverge. Or, if we can find experts in specific areas to participate, we can leverage their arguments to help get more realistic transcripts to train from.
Testing the five properties as predictors. The framework in Figure 6 makes falsifiable predictions. We can score a set of new governance proposals on the five dimensions, run them through LidaSim, and check whether the scoring predicts the simulation outcome. If the properties genuinely explain variance across proposals, this would give governance researchers a quick diagnostic tool — and publishing the scoring rubric openly would let others test it on their own policy proposals.
Expanding the policy space. Our current focus is compute governance. The same framework applies to model evaluation mandates, deployment restrictions, AI lab insurance liability, and safety legislation — all of which interact with hardware governance in ways worth exploring separately.
Conclusion
We built LidaSim in a hackathon weekend to test a simple question: can AI-powered simulations of real public figures help stress-test governance proposals before they face real political scrutiny? The system won first prize at the hackathon, and we intend to continue in this research direction with backtesting and human-in-the-loop runs.
The biggest practical takeaway is the five-property framework. If governance proposals succeed when they are proportionate, unilaterally implementable, privacy-preserving, multi-criterion triggered, and coalition-coherent — and fail when they're not — that's an actionable diagnostic for policy designers. It doesn't require a simulation to apply: you can check a new proposal against these five dimensions in an afternoon. Whether this framework actually holds up is an empirical question, and we intend to test it.
If you work in AI governance, compute policy, or AI safety evaluation, and you'd like to collaborate, we'd love to hear from you. Our code is at github.com/distributed-systems-co/lida-multiagents-research.
